
Internationales Onpage-SEO ist ein spannendes Thema. Wir decken in diesem Beitrag einige Fakten und Eckdaten rund um Suchmaschinen-Optimierung im globalen Kontext ab.
Die Problematik, dass sich eine Sprache nicht 1:1 in eine andere Sprache übersetzen lässt, stellt auch für Suchmaschinen und Computer im Allgemeinen eine große Herausforderung dar. Webauftritte, die international und mit mehreren Sprachen vertreten sind, bieten daher mehrere Sprachversionen einer Website an. Um zu bewerkstelligen, dass Suchmaschinen einen Webauftritt mit jeder vorhanden Sprachversion korrekt indizieren und bei entsprechenden Suchergebnissen ausspielen, muss die Sprache einer Website korrekt eingestellt sein.
Der Inhalt einer jeden Website sollte eindeutig einer bestimmten Sprache, bzw. einer Sprachregion, zugeordnet werden können und ggf. auf andere Sprachversionen der Website hinweisen. Angaben über die Sprache kann man zwar prinzipiell ohne großes technisches Hintergrundwissen in der Google Search Console einstellen. Dieses Vorgehen ist jedoch stark umstritten, da es mit dieser Methode öfters zu Problemen führt. Ein Problem welches beispielsweise auftreten kann ist, dass Zielseiten bestimmter Länder in den Suchmaschinen anderer, auch anderssprachiger, Länder auftauchen. Manchmal hat jene Methode auch schwerwiegende Ranking-Verluste eines Shop-Ablegers zur Folge. Oder aber Google ignoriert das sog. Geotargeting, sprich die Ausrichtung eines Online-Shops auf ein bestimmtes Zielland oder eine Zielregion, über die Google Search Console sogar komplett.
Aufgrund all dieser Probleme wird daher eine alternative Methode zu Festlegung der Sprache empfohlen. Eine technische und viel saubere Lösung ist das language- und das hreflang-Tag. Sie geben Suchmaschinen einen stärkeren Hinweis darauf in welcher Sprache ein Web-Dokument verfasst wurde. Die beiden Tags werden im HEAD-Bereich einer HTML-Datei festgelegt.
Dieser Beitrag ist in folgende Unterkapitel untergliedert. Klicke auf einen Begriff um direkt zu diesem Abschnitt zu gelangen.
- language-Tag
- hreflang-Attribut im alternate-Tag
- Duplicate Content
- Canonical-Tag
- Canonical-Tag richtig verwenden
- Canonical-Nutzung für URL mit GET-Parametern
- Canonical-Nutzung für mobile Seiten
- Canonical-Nutzung für ähnliche Seiten (Keyword-Kannibalisierung)
- Canonical-Nutzung in der Paginierung
- Content
- Indexierungsgrenze
- Entfernen von Seiten und Verzeichnissen
- Domainkonzept und -management
- Regionaler Content für gleichsprachige internationale Webseiten am Beispiel DACH
- Sprachliche Besonderheiten
- Unterschiedliche Inhalte aufgrund unterschiedlicher Prioritäten
- Unterschiedliche Keywords
- Fazit
language-Tag
Mit dem language-Tag legt man fest, in welcher Sprache der Inhalt einer Seite erstellt wurde. Der language-Tag ist aus diesem Grund sehr wichtig für internationales Onpage-SEO.
Der language-Tag sieht wie folgt aus:
<meta name="language" content="de-DE">
Seit Einführung von HTML5 ist es möglich, bereits dem HTML selbst ein Attribut mit den Sprachinformationen hinzuzufügen. Das Code-Snippet aus Kapitel 2 kann somit wie folgt erweitert werden:
<html lang="de">
<head>
<meta name="language" content="de-DE">
</head>
<body></body>
</html>
Das Language-Tag ist kein direkter Rankingfaktor. Google ist durchaus in der Lage, indexierte Seiten selbst einer Sprache zuzuordnen. Allerdings helfen Angaben über die Sprache in der Kopfzeile des HTMLs Google ungemein dabei, Webseiten korrekt zu indexieren und zuzuordnen. Das wird gerade im deutschsprachigen Raum (Deutschland, Österreich und Schweiz) dringend empfohlen, da Google aufgrund der marginalen Sprachunterschiede extreme Schwierigkeiten hat, die Seiten den korrekten Ländern zuzuordnen.
hreflang-Attribut
Internationale Online-Shops sind beispielsweise in den Ländern Deutschland, Österreich, Schweiz und Liechtenstein mit oftmals demselben Shop-Design und derselben Technik vertreten. Im Groben unterscheiden sich die Shops lediglich in der Währung (Euro und Schweizer Franken) und in wenigen Teilen im Artikelstamm. Es gibt Artikel, die aus rechtlichen Gründen in manchen Ländern zum Beispiel nicht verkauft werden dürfen oder deren Artikelbezeichnung gegen Gesetze einzelner Länder verstößt. Das bedeutet, die Online-Shops ähneln sich sehr. Sucht man nach dem Namen des Online-Shops auf Google, so wird in Deutschland, Österreich, Liechtenstein und der Schweiz jeweils immer der korrekte Online-Shop angezeigt. Grund hierfür ist mitunter der hreflang-Tag.
Sind mehrere Versionen einer Website vorhanden, so gibt es neben dem language-Tag noch eine weitere Meta-Angabe, um einer Suchmaschine den Zusammenhang zwischen verschiedenen Versionen einer Website im Internet aufzueigen: das hreflang-Attribut im alternate-Tag. Mit diesem Tag wird sichergestellt, dass die richtige Website-Version dem richtigen Zielmarkt zugeordnet wird. Google ist zwar prinzipiell in der Lage, selbst Webseiten einer Sprache zuzuordnen. Hierbei treten jedoch gelegentlich Fehler auf, die sich deutlich negativ auf den Sichtbarkeitsindex und der damit zusammenhängenden Präsenz in Suchmaschinen auswirken können. Erst die Implementierung des hreflang-Attributs gibt Google das eindeutige Signal über die gewünschte geografische Ausrichtung.
Das hreflang wird ebenfalls im HEAD-Bereich angegeben und sieht wie folgt aus:
<link rel="alternate" href="https://www.pearl.de/" hreflang="de-DE">
<link rel="alternate" href="https://www.pearl.at/" hreflang="de-AT">
<link rel="alternate" href="https://www.pearl.ch/" hreflang="de-CH">
Das hreflang-Attribut sollte auf jeder Unterseite eines gesamten Webauftritts im HEAD-Bereich mit der entsprechend zusammengehörigen Seite der anderen Sprachversion angegeben werden, sprich bspw. auch auf Produktseiten eines Online-Shops:
<link rel="alternate" href="https://www.pearl.de/kategorie/produkt/" hreflang="de-DE">
<link rel="alternate" href="https://www.pearl.at/kategorie/produkt/" hreflang="de-AT">
<link rel="alternate" href="https://www.pearl.ch/kategorie/produkt/" hreflang="de-CH">
Der Wert des Attributs hreflang legt die Sprache einer alternativen URL im Format ISO 639-1 und optional auch die Region im Format ISO 3166-1 Alpha 2 fest. Zum Beispiel:
- de: deutsche Inhalte, unabhängig von der Region
- en-GB: englische Inhalte für Nutzer in Großbritannien
- de-ES: deutsche Inhalte für Nutzer in Spanien
Ein häufiger Fehler beim Einsatz von hreflang-Angaben sind fehlende Bestätigungslinks. Wenn Seite 1 auf Seite 2 verweist, muss Seite 2 in jedem Fall zurück auf Seite 1 verweisen. Falls dies nicht für alle Seiten mit hreflang-Angaben der Fall ist, werden die Annotationen möglicherweise ignoriert oder nicht richtig interpretiert.
Das alternate-Tag sollte zu jeder im Netz auffindbaren Version der Website angegeben werden – auch zu RSS Feeds von Blogs und weiteren Duplikaten eines Webauftritts.
Im April 2013 hat Google eine Möglichkeit zur Angabe einer Standard-Sprachversion eingeführt. Mithilfe dem sog. Link-Attributs hreflang=“x-default“ ist es möglich „eine Default-Seite für alle nicht weiter definierten Sprachversionen“ festzulegen. Diese Kennzeichnung empfiehlt sich besonders für übergeordnete Webseiten, die beispielsweise eine Sprachvorauswahl anbieten, damit ein Kunde direkt zu der für ihn vorgesehenen Sprache gelangen kann oder für Unterseiten, die nicht bei allen Sprachversionen verfügbar ist.
Das hreflang=“x-default“ wird wie folgt verwendet. Die URL http://language-overview.com/ steht hierbei stellvertretend für eine übergeordnete Seite, die dem Kunden eine Sprachauswahl anbietet. Dieser kann keine genaue Sprache zugeordnet werden:
<link rel="alternate" href="http://example.de/" hreflang="de-DE">
<link rel="alternate" href="http://example.at/" hreflang="de-AT">
<link rel="alternate" href="http://example.ch/" hreflang="de-CH">
<link rel="alternate" href="http://language-overview.com/" hreflang="x-default">
Die Auszeichnung einer Seite mit dem Attribut hreflang kann sich direkt auf das Ranking auswirken und ist daher unabdingbar für internationales Onpage-SEO. Bei einer Suche nach einem bestimmten Suchbegriff tauscht Google die Sprachversion einer Website durch die für das Land vorgesehene Seite entsprechend aus. Dabei muss diese Seite nicht primär ranken.
Mit dem hreflang-Attribut ist die Möglichkeit geschaffen, ein und denselben Internetauftritt in mehreren Ländern – sowohl gleich- als auch mehrsprachigen Ländern – zu haben, ohne dass jener als Duplicate Content eingestuft wird. Es empfiehlt sich dennoch auch einen userzentrierten Ansatz zu verfolgen und von Land zu Land unterschiedlichen Content anzubieten.
Duplicate Content
Ein sehr häufiges Problem internationaler Websites sind doppelt oder mehrfach vorhandene gleiche bzw. sehr ähnliche Inhalte. Dieses Problem wird als Duplicate Content (auch Double Content oder kurz DC) bezeichnet und meint im Speziellen, dass unter verschiedenen URLs dieselben oder sehr ähnliche Inhalte zu finden sind.
Seit dem Panda-Update, nach dem Google 2011 durch gezielte Algorithmusänderungen die Qualität von Websites stärker im Ranking berücksichtigt, spielt Duplicate Content bei der Suchmaschinen-Optimierung eine überwiegende Rolle. Suchmaschinen versuchen, für den Nutzer immer das bestmögliche Ergebnis anzuzeigen. Bestmöglich bedeutet im Falle des Duplicate Contents auch möglichst vielfältig. Suchmaschinen wie Google gehen hierbei systematisch vor und filtern von einem Set an unsortierten Inhalten Duplikate heraus um so die Ergebnismenge weiter zu reduzieren. Denn Suchmaschinen arbeiten effizient, dies bedeutet einerseits, dass eine Seite mit demselben oder ähnlichem Inhalt nicht in den Suchmaschinen-Index aufgenommen wird. Andererseits, dass Nutzer einer Suchmaschine für eine Suche nur das beste Ergebnis erhalten sollen.
Doch ab wann gelten zwei oder mehrere ähnliche Seiten im Netz als Duplicate Content? Wie stark wirkt sich eine Abstrafung seitens Google auf das Ranking aus, wenn sich zwei Seiten ähneln? Und zuletzt: Wie kann man Duplicate Content gezielt vermeiden?
Webseiten – im besonderen Online-Shops – arbeiten oft mit einer linken und/oder rechten Seitenleiste. Innerhalb dieser Bereiche werden beispielsweise eine Navigation, Filter-Optionen, ein USP, Trust Elements, aktuelle Angebote, wichtige Links oder Social Media Buttons gesetzt. Auch im Navigations-Menü und im Footer sind in der Regel auf jeder Seite eines Webauftritts ein und derselbe Inhalt zu finden. Das ist aus Sicht eines konsistenten Designs und der Benutzerfreundlichkeit auch gut so. Google wertet aus diesem Grund nur über den Main Content aus, ob sich innerhalb dessen ein ähnlicher Inhalt wie auf einer anderen Seite befindet, oder nicht.
Häufige Ursachen für Duplicate Content sind:
- Desktop und Mobil-Version eines Webauftritts sind über getrennte Domains erreichbar (domain.de und m.domain.de)
- Druckversion einer Website, die über einen GET-Parameter ausgegeben wird und dem Originaldokument inhaltlich gleicht (domain.de/datei.php?version=print)
- Parameter-URLs mit Suchfiltern, Konfigurationen von Produkten, Sortierungsparameter oder Tracking-IDs (domain.de/?s=keyword)
- Domain ist erreichbar über den Domainnamen mit vorangestelltem www. und ohne (www.domain.de und domain.de)
- Domain ist erreichbar über HTTPS und HTTP und liefert hierbei dieselben Seiten aus (https://www.domain.de und http://www.domain.de)
- Domain ist sowohl mit Groß- als auch Kleinbuchstaben zu derselben Seite erreichbar (example.com/page/ und example.com/PAGE/)
- URL einer Unterseite ist mit und ohne Trailing Slash (Schrägstrich am Ende einer URL) aufrufbar (domain.de/unterseite und domain.de/unterseite/)
All diese Probleme lassen sich mit der technischen Onpage-Optimierung von Webseiten beseitigen. Doch interessanter ist viel mehr die Frage: Ab wann gelten zwei ähnliche Inhalte als Duplicate Content? Wie problematisch ist es, wenn eine Seite zu einem gewissen Prozentsatz mit einer anderen übereinstimmt?
Um diese Fragen beantworten zu können ist es hilfreich zu wissen, wie Suchmaschinen Duplicate Content überhaupt erkennen. In der SEO-Branche ist man sich nicht hundertprozentig sicher, welcher Algorithmus hierfür verwendet wird. Sehr wahrscheinlich ist aber der Einsatz des W-Shingle-Algorithmus. Die Anwendung des Shingle Algorithmus funktioniert wie folgt:
- Der Text einer Seite wird in reinen Text umgewandelt und von sämtlichen Formatierungen befreit.
- Der Text wird in sog. Shingles unterteilt. Ein Shingle wird in eine vorher festgelegte Anzahl an Wörtern (z.B. drei Wörter) eingeteilt, die ineinander greifen wie Schuppen (engl. Shingle). Pro Shingle wird jeweils das erste Wort mit dem im Text folgenden nächsten Wort ausgetauscht. Somit wird der Satz Das ist ein guter Beispieltext. in die Shingles [Das, ist, ein], [ist, ein, guter], [ein, guter, Beispieltext] und [guter, Beispieltext, .] gegliedert.
- Um die Shingles auszuwerten werden nun die Shingles von einem Text mit den Shingles eines zweiten Textes verglichen. Die Anzahl der identischen Singles geteilt durch die Gesamtanzahl an Shingles ergibt einen prozentualen Wert an Ähnlichkeit der beiden verglichenen Texte.
Das bedeutet, dass sich Webseiten in eine prozentuale Ähnlichkeit einstufen lassen. Denn es ist unbestreitbar, dass es – wenn auch nur zu kleinen Teilen – Textbausteine gibt, die auf vielen anderen Webseiten vorkommen. Bespielweise verwendete Zitate von Experten, Schriftstellern und Philosophen können unter Umständen auch auf anderen Seiten vorkommen. Zitate können im Gegensatz zu anderen Textpassagen jedoch recht einfach von der Duplicate Content Problematik befreit werden. Durch das semantische HTML-Element <blockquote> kann ein Zitat nicht nur deutlich vom Rest des Textes hervorgehoben werden, sondern wird auch von Suchmaschinen als solches erkannt und wird demnach bei der Duplicate Content Problematik berücksichtigt. Man hat daher nicht zu befürchten, dass eine Seite mit Zitaten aufgrund von Duplicate Content aus den Suchmaschinenergebnissen entfernt wird, so lange das HTML-Element für Zitate wie folgt im Quelltext angegeben wird:
<blockquote cite="Name des zitierten Autors oder der Quelle">
Zitierter Text in Reinform nach den geltenden Zitierregeln
<cite>Name des zitierten Autors oder der Quelle</cite>
</blockquote>
Zitate sollten jedoch nicht im Übermaß verwendet werden. Hierbei kann man sich an die bei wissenschaftlichen Arbeiten geltende Faustregel orientieren, welche bekanntlich bei max. 10% liegt. Es ist offensichtlich, was Matt Cuts in einem YouTube-Video im Kanal der Google Webmaster sagt: Ein Artikel komplett zu zitieren – oder gar mehrere Artikel – sollten zwingend vermieden werden.
Matt Cutts, Webmaster bei Google und in der SEO-Szene liebevoll genannte Spamjäger und Sprachrohr Googles, versichert, dass es immer wiederkehrende Bereiche gibt, die auf vielen Seiten desselben aber auch auf externen Webauftritten vorkommen und nicht als Duplicate Contenteingestuft werden. Hierbei sollte jedoch unterschieden werden. Auf dem YouTube Kanal der Google Webmasters spricht Matt Cutts davon, dass
”„one part of that site, one entire section of that site is entirely defined by maybe just doing a news search, maybe just searching for keywords and press releases – whatever it is – it sounds like it’s pretty auto-generated ... it’s probably not worth just having automatically-generated stuff that could be Duplicate Content, because everybody else has access to the same, you know, article bank directories, or the same press releases ... or something like that"
Matt CuttsWebmaster bei Google
Duplikater Inhalt externer Seiten sollte vermieden werden, wohingegen er wiederkehrenden eigenen Content von der eigenen Website als weitgehend unproblematisch bezeichnet. Rückführend lässt sich also für Duplicate Content folgende Definition erschließen: Google stuft erst dann eine Seite als Duplicate Content ein, wenn der Main Content Bereich einer Seite im Vergleich zu einer anderen einen bestimmten Grad an Ähnlichkeit übersteigt. Ulrich Lutz vom deutschen Google Search Quality Team definiert Duplicate Content sogar noch einfacher: „Laut Google sind DCs ‚…umfangreiche Contentblöcke, die auf mehreren Seiten identisch sind’“. In der SEO-Szene wird oft von einem Wert von 80% gesprochen – eine genaue prozentuale und mathematische Angabe zu welch einem Prozentsatz sich zwei oder mehrere Seiten unterscheiden müssen, um nicht als Duplicate Content eingestuft zu werden, ist hierbei jedoch nicht möglich. Ulrich Lutz legt nahe, man solle seinen Verstand benutzen und durch eigenen Content gegenüber zu einem vergleichbaren Content einen möglichst hohen Mehrwert für den User zu schaffen.
Eine weitere Frage die sich ergibt ist, wie sich doppelte Inhalte auf das Ranking auswirken. Positiv ist, dass man beim Produzieren von Duplicate Content vorerst keine Abstrafung seitens Google zu befürchten hat. Es ist vielmehr das Problem, dass eine Seite gar nicht erst in den Suchergebnissen auftaucht.
Website, die Duplicate Content aufweisen, werden seit dem Panda-Update (2011) in einen sog. Supplemental Index verschoben. Das ist ein Suchmaschinen-Index, der fernab des normalen Indexes liegt. Von dem Supplemental Index können keine Einträge in der Top 10 Liste von Google angezeigt werden. Google kann im Falle einer Suche nach Duplicate Content diesen Supplemental Index anzeigen.
”Google stuft erst dann eine Seite als Duplicate Content ein, wenn der Main Content Bereich einer Seite im Vergleich zu einer anderen einen bestimmten Grad an Ähnlichkeit übersteigt.
Canonical-Tag
Die URL-Kannonisierung mittels rel="canonical" ist ein sehr effektives Mittel für internationales Onpage-SEO, um Probleme mit Duplicate Content in den Griff zu bekommen. Mit rel="canonical" lässt sich die bevorzugte Version eines Inhalts, der auf mehreren URLs verfügbar ist, ausweisen. Der Tag funktioniert sowohl bei externen als auch internen Inhalten.
Eine Kannonisierung hat den bedeutenden Vorteil, dass bei einem Webauftritt durch versehentlich geschaffenem duplikaten Inhalt kein wertvolles SEO-Potenzial verloren geht. Es ist vielmehr das Gegenteil der Fall. Verlinkungen zur richtigen Version einer Seite vereint das Ranking aller verlinkten Seiten und stärkt somit die primäre Version.
Es empfiehlt sich den Canonical-Tag immer dann zu verwenden, wenn eine ähnliche Version einer Website nicht mit einer 301-Weiterleitung zum Originaldokument aus Funktionssicht gleichzusetzen ist. So sollte die Kannonisierung beispielsweise nicht benutzt werden, wenn ein und dieselbe Website über HTTP und über HTTPS erreichbar ist, oder mit www. im Domainname und ohne. Hierfür sollte eine permanente Weiterleitung (301) verwendet werden. Zudem sind 301-Weiterleitungen auch nur dann zu empfehlen, wenn sie mindestens ein halbes Jahr im Einsatz ist. Das rel="canonical" sollte auch nicht benutzt werden, um auf verschiedene Sprachversionen oder auch die Lokalisierung zu weisen. Ebenso wenig sollte dieses Attribut dazu genutzt werden, um PageRank Sculpting zu missbrauchen.
Prinzipiell gilt es, das rel=“canonical“ so selten wie möglich einzusetzen, da auch jede Seite mit dem Canonical-Tag in den Suchmaschinenindex aufgenommen wird und somit schnell das Crawlbudget ausgeschöpft ist.
Wird über den Canonical-Tag keine bevorzugte URL gekennzeichnet, wählen Suchmaschinen von selbst, welche URL in den Suchergebnissen angezeigt werden, da für einen Inhalt immer nur eine URL angezeigt werden kann. Davon ist jedoch prinzipiell abzuraten, da eine Google nicht immer die vom Autor priorisierte Seite wählt.
Es gibt einige Fälle in denen rel="canonical" falsch angewendet wird. Insgesamt wurden bei 10.000 Seitenaufrufen von Twitter.com ganze 1.902 Fehler mit nicht einwandfreien Setzen des Canonical-Tags aufgewiesen. Um dies zu vermeiden folgt in den folgenden Kapiteln eine übersichtliche Auflistung zur korrekten Verwendung der Kannonisierung.
Canonical-Tag richtig verwenden
Es gibt prinzipiell zwei Methoden die Kannonisierung anzuwenden: über das HTML-Markup oder im HTTP-Header. Die bekannteste Methode ist das Setzen des Tags in den HEAD-Bereich des HTML-Markups wie folgt:
<html lang="de">
<head>
<meta name="language" content="de-DE">
<link rel="canonical" href="http://www.example.com/page/">
</head>
<body></body>
</html>
Die Variante des Setzens des rel=“canonical“ über den HTTP-Header eignet sich bei Nicht-HTML-Dokumenten, wie es bei Druckversionen, PDFs und Bildern der Fall ist:
HTTP/1.1 200 OK
Content-Type: application/pdf
Link: <http://www.example.com/page/; rel="canonical"
Content-Length: 3106
Bei der Canonical-Nutzung sollten prinzipiell immer absolute URLs gesetzt werden. Es sollten demnach keine gekürzten Verweise wie //www.example.
com oder im Falle einer internen Verlinkung lediglich /page/. Außerdem sollte darauf geachtet werden, dass die Ziel-URL eines jeden Canonical-Tags den HTTP-Status 200 OK besitzen sollte.
Canonical-Nutzung für URL mit GET-Parametern
GET-Parameter, auch oft URL-Parameter genannt, schleichen sich relativ schnell in die URL-Struktur einer Seite ein. Beispielweise durch Tracking-Parameter entstehen oft unterschiedliche URLs zu ein und derselben Seite:
- https://www.pearl.ch
- https://www.pearl.ch/?vid=351
Anders, als sein häufiges Auftreten im Netz vermuten lässt, sollten Seiten mit GET-Parametern ebenfalls kannonisiert werden, um sicherzustellen, dass Google & Co. stets die gesamte Linkpower der Haupt-URL zuweist. Durch die Implementierung des folgenden PHP-Skripts im Header jeder HTML-Datei (oder besser noch in der zentralen Header-Datei) kann hierbei recht leicht Abhilfe geschaffen werden:
<?php
if ( count($_GET) ) :
$uri = explode( '?', $_SERVER['REQUEST_URI'], 2 );
echo '<link rel="canonical" href="https://'.$_SERVER['HTTP_HOST'].$uri[0].'">';
endif;
?>
Dieses Code-Snippet kann prinzipiell auf jeder Seite implementiert werden, so lange kein anderes System zum Setzen von Canonicals in die Quere kommt. Denn es sollte stets darauf geachtet werden, dass lediglich ein Canonical-Link auf einer Seite gesetzt wurde, andererseits ignoriert Google sämtliche Kannonisierungen der Seite.
Canonical-Nutzung für mobile Seiten
Viele Online-Shops nutzen jeweils getrennte Seiten für die Anzeige auf einem Desktop und einem Mobilgerät, wie beispielsweise www.pearl.de und m.pearl.de. Der Inhalt beider Seiten gleicht sich zu einem hohen Prozentteil. Responsive Seiten werden zwar von Google klar bevorzugt, aber auch zwei separate Seiten werden von Suchmaschinen geduldet. Um Duplicate Content hierbei zu vermeiden und Google genau zu sagen, welche Seite für welches Endgerät ist, bedarf es auch hier der Nutzung des Canonical. Die mobile Seite weist über den Canonical-Tag auf die Desktop-Variante. Diese Version sollte in das Root-Verzeichnis der Toplevel-Domain leiten und folgende Variante einer alternate-Angabe im HEAD des HTML-Dokuments beinhalten:
<link rel="alternate" media="handheld", only screen and (max-width: 640px) href="https://m.domain.de/">
Der Inhalt beider Seiten sollte sich hierbei in etwa entsprechen, die Sprache sollte dieselbe sein und ein Gerät dieser Zuordnung sollte mit einer Weiterleitung auf die mobile Variante umgeleitet werden um die korrekte Indexierung seitens Google sicherzustellen.
Canonical-Nutzung für ähnliche Produkte (Keyword-Kannibalisierung)
Keyword-Kannibalisierung auf Websites„findet statt, wenn sich unterschiedliche Produkte eines Unternehmens in direkter Konkurrenz zueinander befinden. Das bedeutet, dass sie die gleiche Zielgruppe ansprechen und sich gegenseitig Marktanteile rauben.
Ähnliche Produkte auf Websites, die sich in Ausführung, Farbe, Kapazität, Leistung oder sonstigen Eigenschaften nur minimal unterscheiden, werden aufgrund der inhaltlichen Ähnlichkeit von Suchmaschinen schnell als Duplicate Content eingestuft. Damit stehen sie in direkter Konkurrenz zueinander. Dies ist bei Online-Shops sehr oft der Fall. Um eine Abstrafung seitens Google diesbezüglich zu vermeiden greifen Suchmaschinen-Optimierer gerne auf die Kannonisierung zurück.
Das hat den Vorteil, dass die Produkte nicht mehr in direkter Konkurrenz zueinanderstehen und so keine Abstrafung zu befürchten ist aufgrund von Duplicate Content.
Canonical-Nutzung in der Paginierung
Paginierungen sind oft bei Suchfunktionen und dessen Suchergebnisseiten zu finden. Oft werden sehr viele Suchergebnisse für bestimmte Suchbegriffe ausgespuckt. Über die Paginierung wird eine Zerstückelung dieser Ergebnisse auf mehrere Seiten hinweg bewerkstelligt. Mehrere Canonical-Tags auf einer Seite führen zu einem Indexierungsfehler. Es werden sämtliche Kannonisierungen ignoriert. Daher muss bei der Paginierung darauf geachtet werden, dass der Canonical richtig gesetzt wird.
Damit die einzelnen Seiten nicht als Duplicate Content eingestuft werden, sollte das Canonical korrekt für Paginierungen eingesetzt werden. Wird das Canonical gleich wie beim Duplicate Content benutzt, so kann es zu Indexierungs-Fehlern führen, da es nur für DC ausgelegt ist und paginierte Seiten nicht denselben Inhalt aufweisen. Um zu bewerkstelligen, dass Suchmaschinen Paginierungen richtig verstehen und die einzelnen Paginierungsseiten keinerlei Einfluss auf das Ranking haben, sollte der HTML-HEAD-Bereich wie folgt erweitert werden:
| Selbstreferenzierender Canonical | |
|---|---|
| http://example.com/page/ | <link rel="canonical" href="http://example.com/page/"> |
| http://example.com/page/?seite=2 | <link rel="canonical" href="http://example.com/page/"> |
| http://example.com/page/?seite=3 | <link rel="canonical" href="http://example.com/page/"> |

Content
Der Content ist der Bereich der Website, der einzigartig, informationsreich und userrelevant sein sollte. Er wird mit Medien wie Bilder, Videos, Infografiken, Icons und zuletzt auch Texten angereichert, um für den Nutzer – und die Suchmaschinen – einen möglichst qualitativ hochwertigen Content zu liefern.
Der Content ist einer der wichtigsten Ranking-Faktoren für Onpage-SEO im Allgemeinen und somit auch für internationales Onpage-SEO.
Der Begriff Content ist jedoch hierbei von dem Begriff Information abzugrenzen. Mit Information ist die Quelle des Wissens gemeint, wohingegen beim Content eher das Vermitteln dieses Wissens auf eine möglichst leichte Art und Weise im Vordergrund steht. Im Web gibt es verschiedene Arten an Content:
- Unique Content: Als Unique Content bezeichnet man Inhalte im Web, die auf keiner anderen Webseite vorhanden und somit unique (einzigartig) sind.
Die Einzigartigkeit von Text ist ein wichtiger Ranking Faktor für Suchmaschinen und ist vergleichbar mit dem Unique Selling Point (USP) eines Produktes. - Evergreen Content: Evergreen Content ist eine Bezeichnung für Inhalte oder Themen, die in journalistischen Werken oder auf Websites publiziert wurden. Diese Themen haben einen zeitlosen Charakter und sind in der Regel weder an saisonale noch epochale Bezüge gebunden und stellen für den User lange Zeit einen Mehrwert dar. Im Bereich der Suchmaschinenoptimierung kann Evergreen Content nützlich sein, um dauerhaft frische Backlinks sowie Traffic zu erhalten. Ein gängiges Beispiel für Evergreen Content ist ein Lexikoneintrag.
- Thin Content: Als Thin Content bezeichnet Google Inhalte von Websites, die den Anforderungen an die Webmaster Guidelines nicht genügen und dem Besucher inhaltlich keinen Mehrwert bieten.
Offensichtlich sollten Webseiten-Betreiber davon absehen, Seiten mit Thin Content zu erstellen. Viel wichtiger ist es, sich von der Konkurrenz abzusetzen in dem man mithilfe von Unique Content qualitativ hochwertige und für den Nutzer relevante, unterhaltsame und leicht verständliche Inhalte erstellt. Das gilt insbesondere seit dem Panda Update seitens Google im Jahre 2011. Webseiten mit Unique Content zu erstellen, ist vor allem dann wichtig, wenn dasselbe Produkt auf einer kommerziellen Seite auch bei der Konkurrenz oder auf der Website der Marke selbst angeboten wird. Hier kann man Google – und dem Nutzer – am besten zeigen, wie gut man einen Unique Content erstellen kann. Mit einem unique Text ist die Wahrscheinlichkeit wesentlich höher bei einer Produktsuche auf den oberen Positionen im Index zu erscheinen. Beinhaltet eine Seite keinen Unique Content ist es außerdem prinzipiell möglich, dass diese als Duplicate Content eingestuft wird, welche eine Abstrafung der Seite zur Folge hat.
Ein gewisses Maß an Seiten mit Evergreen Content sollte jede Website im Netz haben um Backlinks und Traffic von referenzierenden Seiten zu erhalten. Einen Evergreen Content zu erstellen ist recht leicht umsetzbar mithilfe von Wikis, Lexikas, Merkblätter (auch als PDF-Download), Top-Ranking-Listen und Vergleich weiterer Angebote im Netz, Handbücher, Ratgeber oder mithilfe von historischen Artikeln zu Geschichte, Sagen, Mythen und Verschwörungen. Bei der Erstellung eines Evergreen Contents sollte der Autor die vermittelnden Informationen so anreichern, dass anzunehmen ist, dass sie auch in ein paar Jahren immer noch aktuell sind.
Evergreen Content auf einer Website, die sich in den Köpfen derer User bereits als eine wertvolle Marke etabliert hat, kann besonders vorteilhaft sein. Referenzierende Webseiten greifen hierbei auf die Expertise dieser Marke zurück und stärken dadurch den eigenen Content.
Content-Wachstum und -Aktualisierung
Google liebt aktuelle Inhalte. Seit dem Freshness Update im November 2011 bevorzugt Google Inhalte, die neuer sind, besser, obwohl eine ältere Seite bisher ein besseres Ranking hatte. Auf der Startseite einer erfolgreichen Website sollte sich daher in jedem Fall ein Bereich befinden, der andauernd aktualisiert wird. Das können aktuelle Informationen über das betreibende Unternehmen sein oder ein Blog, der regelmäßig Beiträge zu aktuellen Themen enthält. Wichtig ist hierbei nicht die Quantität der Artikel, sondern vielmehr die Qualität:
”„There’s no minimum length, and there’s no minimum number of articles a day that you have to post, nor even a minimum number of pages on a website. In most cases, quality is better than quantity. Our algorithms explicitly try to find and recommend websites that provide content that’s of high quality, unique and compelling to users. Don’t fill your site with low-quality content, instead work on making sure that your site is the absolute best of its kind."
John MüllerDoes short content treat as low quality content?
Ein Online-Shop bringt von Zeit zu Zeit neue Artikel auf den Markt. Diese sollten im besten Fall beworben werden. Sowohl auf internen Seiten als auch auf externen. Gerade positive Berichte von der Presse sowie Empfehlungen von erfolgreichen und vertrauensvollen Blogs kann das Ranking verbessern und das Vertrauen des Nutzers zu diesem Online-Shop erweitern.
Auch bereits bestehende Seiten sollten aktualisiert und angepasst werden. Websites mit nicht aktuellen Inhalten können beim Nutzer schnell den Eindruck hinterlassen, dass die Seite nicht sorgfältig genug gepflegt wird. Das Vertrauen zu dieser Website wird dadurch ungemein verschlechtert und kann im schlimmsten Fall zum Verlassen der Seite führen.
Indexierungsgrenze
Suchmaschinen haben Grenzen. Ein weiterer Grund, der für ein stetiges Content-Wachstum spricht, ist die Indexierungsgrenze. Eine Suchmaschine wie Google berechnet für jede Domain vor einer Indexierung ein bestimmtes sog. Indexierungsbudget. In diesem Budget wird festgelegt wie viele und welche Seiten eines Internetauftritts in den Suchmaschinen-Index aufgenommen werden.
Google ist durch das vorhandene Suchvolumen eines Suchbegriffs durchaus in der Lage, selbst Seiten auszuwählen, die für den Nutzer womöglich am interessantesten sind. Die Suchmaschine sortiert daher vermeintlich für den Nutzer uninteressante Seiten aus und nimmt diese nicht in den Index auf. Aus diesem Grund sollte man für die Nutzer einer Suchmaschine uninteressanten Seiten schon im Vorherein mittels noindex sperren. Diese Einstellung kann im HEAD einer HTML-Datei wie folgt vorgenommen werden:
<meta name="robots" content="noindex">
Im Abschnitt über Duplicate Content wurde bereits erklärt, dass effiziente Suchmaschinen keinen Duplicate Content in den Suchmaschinenindex aufnehmen. Kannonisierte URLs werden zwar in den Suchmaschinenindex aufgenommen, werden jedoch in den Suchmaschinenergebnissen nicht angezeigt. Sie gehen damit zwangsläufig auch auf Lasten des Indexierungsbudgets.
Entfernen von Seiten und Verzeichnissen
Seiten und Verzeichnisse bei Webseiten sollten jederzeit behutsam entfernt werden. Wird eine bereits indexierte Seite bei einem erneuten Crawl nur von einer 404-Seite mit dem dazugehörigen Statuscode empfangen, so wird die Seite aus dem Suchmaschinenindex gelöscht. Dadurch verschenkt man unnötig sog. Linkjuice. Mit Link Juice wird die Verteilung von Backlinks innerhalb einer Webseite und die Stärke oder Reputation dieser Links beschrieben.
Es ist daher sinnvoll vor dem Löschen einer Seite bzw. eines Verzeichnisses diese auf eine thematisch relevante Seite umzuleiten. Dadurch wird der PageRank der bisherigen Seite eins zu eins auf die neue übertragen.
Die Anzahl der indexierten Seiten ist ein indirekter Ranking-Faktor. Eine Website mit mehr indexierten Seiten wird von Google öfters indexiert, das Indexierungsbudget ist höher und die Vielfalt der Longtails (Vielfalt an Keyword-Kombinationen, die Google verwenden kann) ist höher. Daher sollte man stets behutsam Seiten und Verzeichnisse von der eigenen Webpräsenz entfernen. Im Allgemeinen macht das Entfernen von Seiten und Verzeichnissen auch nur dann Sinn, wenn der Inhalt der Seite so veraltet (bzw. qualitativ wertlos) ist, dass ein Aktualisieren keinen Sinn mehr macht; oder aber der Inhalt nur von temporärer Bedeutung ist, wie beispielweise ein zeitlich limitiertes Sonderangebot.
Im internationalen Kontext ist in dieser Hinsicht besonders zu beachten, dass Seiten, die in einer Sprachversion entfernt werden auch bei den anderen Sprachversionen entfernt werden sollte. Alternativ sollten zumindest die hreflang-Angaben angepasst werden. Ein Verweis mittels hreflang="x-default" ist denkbar.
Zu hreflang
Domainkonzept und -management
Plant man einen neuen Webauftritt, so führt kein Weg an einem sorgfältig geplanten Domainkonzept vorbei. Dieses Konzept stellt die Weichen für eine langfristige und effektive Möglichkeit, Suchmaschinen-Optimierung zu betreiben. Was ohnehin – ganz unabhängig davon für welches Domainkonzept man sich entscheidet – schon bekannt ist, so sollten in jeder URL sog. sprechende URLs (vgl. Kapitel 2.3.3) verwendet werden. Gerade bei international agierenden Unternehmen gibt es oftmals für jedes Land einen Ableger einer Webseite. Im Internet sind prinzipiell drei verschiedene Varianten an Domainkonzepten aufzufinden:
- ccTLD (cc = country code): www.beispiel.com und www.beispiel.de
- gTLD über Subdomains (g = generic): de.beispiel.com und at.beispiel.com
- gTLD über Unterverzeichnisse (g = generic): www.beispiel.com/de/ und www.beispiel.com/at/
Beispiele im Netz für diese Domainkonzepte sind beispielsweise:
- ccTLD: Amazon.de, Amazon.fr, Amazon.es, Amazon.com, Amazon.co.uk usw.
- gTLD über Subdomains: de.sistrix.com
- gTLD über Unterverzeichnisse: www.apple.com/de/ und www.apple.com/at/
Nutzt man besser eine ccTLD oder eine gTLD für einen internationalen Webauftritt?
Doch welches Domainkonzept ist für internationale Online-Shops und Webauftritte die beste Variante? Mit welchem Domainkonzept kann man langfristig die besten Ergebnisse in Sachen Suchmaschinen-Optimierung erzielen?
Um eine Empfehlung für das ideale Domainmanagement aussprechen zu können, müssen die einzelnen Domainkonzepte voneinander differenziert werden. Je nach Konzept kann die Domainvariante verschiedene Auswirkungen auf die Suchmaschinenoptimierung haben.
Es ist offensichtlich, dass es prinzipiell leichter ist, eine internationale Website über Unterverzeichnisse zu realisieren. Denn sowohl eine Subdomain als auch eine Top-Level-Domain (kurz TLD) müssen einem eigenen Root-Verzeichnis zugewiesen sein – sprich einem separat abgetrennten Bereich innerhalb einer oder mehrerer Server. Jede Domain bzw. Subdomain muss daher eigens per DNS zu genau jenem Bereich zugewiesen werden.
Jedoch ist die URL zu einer Subdomain im Vergleich zu einer URL zu einem Unterverzeichnis aus Sicht der Suchmaschinen prinzipiell gleichzusetzen, was Matt Cutts auf seinem Blog bestätigt. Daher kann im Folgenden ein Domainkonzept mit einer gTLD über Subdomains und einer gTLD über Unterverzeichnisse gleich behandelt werden. Somit bleiben aus Sicht der technischen Suchmaschinen-Optimierung nur noch folgende zwei Domainkonzepte übrig:
- ccTLD
- gTLD
Diese Frage zu beantworten ist schwer, da jedes Konzept an und für sich seine Vor- und Nachteile hat. Gründsätzlich gilt, bei der Nutzung von gTLD profitiert jeder Domainbereich, sprich jedes Land, von dem Ranking-Boost eines anderen Landes, da der Sichtbarkeitsindex der Domain gleichermaßen für alle Länder erhöht wird. Allerdings gibt es hierbei Grenzen. Die Indexierungsgrenze hat gezeigt, dass ein Indexierungsbudget, gerade bei einem schnellen Wachstum einer Webpräsenz, schnell aufgebraucht ist. Bei Nutzung von ccTLDs muss daher jede Seite seine eigene Linkpower und seinen eigenen Sichtbarkeitsindex aufbauen, da jede Domain von Google separat behandelt wird. Gerade in den Anfangszügen eines Webauftritts ist daher das Suchmaschinen-Ranking nicht sonderlich hoch und die Investitionen in Suchmaschinenoptimierung dementsprechend höher. Doch mit jeder Verlinkung der Seite auf einer anderen Seite, genauer gesagt bei einem guten Linkmarketing, zahlt sich diese Strategie aus. Denn teilen sich die jeweiligen Länderversionen bei einem Domainkonzept mit gTLD gerade mal einen Bruchteil des eingehenden sog. Linkjuices, so darf bei den jeweiligen ccTLDs jedes Land die gesamten 100% des Linkjuices für sich beanspruchen. Damit kann folgende These aufgestellt werden: Wenn die Verlinkung auf gemeinsam genutzte Domains (gTLDs) stattfindet, so geht die Linkpower für die eigentlich zu stärkende Länderversion verloren. Diese Verteilung von Investitionen im Link-Marketing im Vergleich zu den Einnahmen über Traffic, der Suchmaschinen als Quelle hat, kann somit eins zu eins auf das Umsatzpotenzial eines Online-Shops übertragen werden.
Zusammenfassend lässt sich somit sagen, dass sich ein Domainkonzept mit ccTLD aufgrund der Indexierungsgrenze, des Link-Juices, der CTR und letztendlich allein schon aus Höflichkeit für die jeweiligen Nationen für größere internationale Webauftritte am ehesten eignet. Jedes Land hat, wie auch das Recht auf eine eigene Flagge, ebenso das Recht auf eine ccTLD. Wozu sollte man den Nutzern in den verschiedenen Ländern eine Domain mit der hierzulande gängigen ccTLD verwehren? Es teilen sich ja auch nicht mehrere Nationen eine Flagge. Denn eine Länderdomain wirkt in diesem Fall stark vertrauensbildend.
”„Verwenden Sie Domains auf oberster Ebene: Damit wir die richtige Version eines Dokuments bereitstellen können, sollten Sie vorzugsweise Domains der obersten Ebene verwenden, um landesspezifischen Content zu präsentieren. Die Website www.ihrebeispielurl.de weist eher auf landesspezifischen Content für Deutschland hin als www.ihrebei
Google SupportDuplizierter Content
spielurl.com/de oder de.ihrebeispielurl.com.“
Um das Konzept mit den ccTLD für jedes Land zu stärken sollte in Anbetracht des Hostings außerdem darauf geachtet werden, dass für jede Domain (mindestens) ein eigener Webserver mit einer eigenen IP innerhalb dieses Landes – oder zumindest mal einen Server-Proxy – zu verwenden, um sowohl Suchmaschinen als auch den Nutzern den Standort des Servers in demselben Land anbieten zu können. Das kann gerade aus datenschutzrechtlichen Gründen für manche Nutzer interessant sein. Für verschiedene Browser gibt es einige nützliche Plug-Ins um den Länderstandort des Webservers anzuzeigen, wie Flagfox für Firefox aber auch IP Whois & Flags Chrome & Websites Rating für Google Chrome.
Es ist offensichtlich, dass bei dem Domainkonzept mit ccTLDs vorausgesetzt sein sollte, dass alle Domains verfügbar sind. Es ist jedoch Aufgabe des Unternehmers, dass bei einem Rollout einer Webpräsenz in einem Land alle etwaigen ccTLD weiterer Länder, in denen ein Rollout grundsätzlich nicht ausgeschlossen ist, ebenfalls gekauft werden. Somit geht man auch einem möglichen Domaingrabbern und Page-Jacking präventiv aus dem Weg. Dieselbe Herangehensweise sollte man auch für sog. Tippfehler-Domains wählen.
Besitzt jedes Land seine eigene ccTLD, beseitig man automatisch das Problem, welches beispielsweise in der Schweiz auftritt. Aufgrund der hierzulande unterschiedlichen Sprachregionen (deutsch, französisch, italienisch) können aus Sicht des ISO 639-1 und des ISO 3166-1 Alpha 2 Formats unschöne Domains resultieren, wie es im Falle der Website von apple.com der Fall ist: In der URL, der für den Schweizer Sprachraum vorgesehen Websites, ergibt sich für die deutschsprachige Schweiz https://www.apple.com/chde/ und für die französischsprachige Schweiz https://www.apple.com/chfr/. Bei einem Domainkonzept mit ccTLD sollten die URLs wie folgt angegeben sein, um den ISO-Formaten gerecht zu werden:
- Deutschsprachige Schweiz: https://www.beispiel.ch/de/ oder https://de.beispiel.ch/
- Französischsprachige Schweiz: https://www.beispiel.ch/fr/ oder https://fr.beispiel.ch/
- Italienischsprachige Schweiz: https://www.beispiel.ch/it/ oder https://it.beispiel.ch/
Die übergeordnete ccTLD https://www.beispiel.ch/ sollte standardmäßig mittels hreflang="x-default" einer Sprache zugeordnet werden (vgl. Kapitel 3.1.1). Außerdem sollte die in dem Browser des Users bevorzugte Sprache erkannt und auf die passende Sprachversion umgeleitet werden.
Anhand dieses Konzeptes profitieren alle Sprach-Ableger der Website am ehesten von dem resultierenden Linkjuice, insofern alle Sprachversionen mit den korrekten Spracheinstellungen signiert wurden.
Regionaler Content für gleichsprachige internationale Webseiten am Beispiel DACH
Es ist sehr verlockend: Verfügt man bereits über einen guten Webauftritt in einer der deutschsprachigen Länder Deutschland, Österreich oder der Schweiz, so ist der Schritt zum Rollout – vorausgesetzt man hat sich auf ein Domainkonzept geeinigt und die ccTLDs sind allesamt verfügbar – in all diesen Ländern vermutlich sehr klein. Jedoch bei großen Seiten mit mehreren tausend Texten kann dies einen enormen Mehraufwand bedeuten. Aufgrund der gleichen Sprachbegebenheiten muss lediglich die Währung in der Schweiz auf Schweizer Franken angepasst werden, die AGBs an die Gesetze und Rechte innerhalb der einzelnen Ländern überprüft werden und eventuelle Ge- und Verbote im Bereich E-Commerce beachtet werden (in der Schweiz beispielsweise gibt es prinzipiell kein gesetzliches Rückgaberecht). Doch ein erfolgreicher internationaler Webauftritt ist viel mehr.
Im Zusammenhang mit Suchmaschinenoptimierung fallen oft Floskeln wie „Content is king“ oder „Wir müssen einen Mehrwert für den User schaffen“. Und genau darum geht es auch, nämlich Content-Marketing.
Es geht also darum, guten Content für den User zu schaffen. Es lässt sich ohnehin ein Trend dorthin beobachten, dass guter und wertvoller Content für den User auch für ein besseres Ranking in den Suchmaschinen zur Folge hat. Es ist kein Geheimnis mehr, dass Google hohe Besucherzahlen und Besuchsdauer positiv bewertet und hohe Bouncerates und Absprungzahlen im Ranking eine schlechte Auswirkung haben. Bei diesem Trend spricht man bei SEO auch von Search Experience Optimization. Der Unterhaltungswert der User und Informationsgehalt der Website entscheidet also über den Qualitätswert einer Website. Ein userzentrierter Ansatz ist also auch bei internationalem SEO ein Muss. Doch die Umsetzung ist alles andere als lapidar und stellt viele Unternehmen vor große Herausforderungen. Die Gründe dafür sind vielfältig: Blindheit für das eigene Produkt, mangelndes technisches Know-how oder zu wenig Verständnis für die individuellen Bedürfnisse der User sind nur einige davon. Doch wie schafft man es, durch qualitativ hochwertigen Content einen Mehrwert und ein Erlebnis für den User zu schaffen? Ein erster Schritt ist sicherlich, die Webpräsenz regional anzupassen.
Sprachliche Besonderheiten
Auch wenn die drei Länder Deutschland, Österreich und Schweiz auf dem Papier dieselbe Sprache sprechen (auch wenn man es nicht immer als solches wahrnimmt entspricht das schweizerdeutsch in der Schriftsprache beinahe exakt dem hochdeutschen) handelt es sich hierbei um 3 unterschiedliche Kulturen. Das bedeutet, dass die User-Gewohnheiten sich von Land zu Land unterscheiden können. Das beginnt schon bei der Begrüßung: Spricht man im norddeutschen von einem Moin, im süddeutschen und im österreichischen von einem Servus, so kann man in der Schweiz gerne mal mit einem Grüezi, Allegra oder einem saloppen Hoi begrüßt werden. Mundarten machen die Seite noch spezieller. Schweizer schätzen es besonders, wenn man sie sprachgerecht anspricht. So steht im Hauptbahnhof in Freiburg im Breisgau über der Info-Tafel der Marke Schwarzwaldfür Touristen groß die Begrüßung: Willkommen – Welcome – Bienvenue – Grüezi.
Schweizer schätzen es besonders, wenn man sie sprachgerecht anspricht:

Info-Tafel mit sprachgerechter Ansprache der Marke Schwarzwald für Touristen im Hauptbahnhof in Freiburg im Breisgau
Schweizer bevorzugen es mit den deutschsprachigen Nachbarländern nicht unter einen Hut gesteckt zu werden. Ein Großteil der Schweizer schätzen Österreich und Deutsche sogar eher als unsympathisch ein und möchten alleine schon deshalb nicht mit jenen in Verbindung gebracht werden. Cicero, ein Magazin für politische Kultur, beschreibt die Schweiz sogar als „das deutschfeindlichste Land Europas“. Ganz so schlimm ist es dann doch nicht: „Nein, es hängt nicht an jeder Bar ein Schild mit dem Aufkleber ‚Deutsche unerwünscht’. Aber man spürt es, an den vielen Kleinigkeiten des Alltags; daran, dass das Lächeln einer Verkäuferin schlagartig schmäler wird, wenn sie bemerkt, es mit einem Deutschen zu tun zu haben.“ Auf einen Online-Shop übertragen bedeutet dies, dass wenn ein Schweizer Website-Besucher merkt, dass er es bei einer Schweizer Seite eigentlich mit einem deutschen Anbieter zu tun hat, so ist er eventuell bereits abgeneigt und zieht womöglich einen original Schweizer Anbieter vor.
Auch wenn offiziell die Schriftsprache in der Schweiz derer in Deutschland (und Österreich) entspricht, so findet man in Schweizer Internet-Foren beispielsweise oft auch das Schweizerdeutsch in Schriftform. Wohingegen in deutschen Foren ausgeschriebene Dialekte selten anzufinden sind. In den Schweizer Foren wird es als Selbstverständlichkeit verstanden, dass man diese Sprache auch versteht und selbst spricht. Markus Renner zog 2004 von Deutschland in die Schweiz und bringt das Schweizer deutsch in zwei knappen Sätzen während eines Interviews mit Spiegel auf den Punkt: „Schwyzerdütsch ist kein deutscher Dialekt, wie Deutsche oft glauben, sondern eine Sprache mit eigenen Vokabeln und eigenen Regeln.“ Nicht nur im umgangssprachlichen, sondern auch im offiziellen Sprachgebrauch lassen sich somit Unterschiede in der Rechtschreibung ausmachen. Besucht man als Deutscher oder Österreicher eine Schweizer Website, so fallen uns schnell die fehlenden ß auf, die in der Schweizer Schriftsprache durch ssersetzt werden. Es unterscheiden sich auch manche Artikel. So heißt es in der CH nicht wie in DE und AT die E-Mail, das Parken, das Ticket, das Fahrrad und der Ausbilder, sondern das E-Mail, das Parkieren, das Billet, das Velo und der Ausbildner. Solche vermeintlichen Schreibfehler können beim Gebrauch auf der jeweiligen länderspezifischen Seite störend wirken und zuletzt das Vertrauen zur Website schwächen. Das Vertrauen spielt ohnehin eine große Rolle beim Online-Kauf: 21% der Kaufabbrüche in Online-Shops kamen durch einen nicht vertrauenserweckenden Shop zu Stande.
Auch Unterschiede in Ansprache und Verabschiedung in einer E-Mail sind von Land zu Land unterschiedlich. Um Fehler zu vermeiden und das Vertrauen dadurch nicht unnötig zu vermindern sollten in der E-Mail-Ansprache folgende Dinge beachtet werden:
| Deutschland | Österreich | Schweiz |
|---|---|---|
| Sehr geehrte Damen und Herren, | Sehr geehrte Damen und Herren! | Sehr geehrte Damen und Herren |
| weiter mit Kleinschreibung. | Weiter mit Großschreibung. | Weiter mit Großschreibung. |
| Mit freundlichen Grüßen, | Mit freundlichen Grüßen, | Freundliche Grüße |
Bei den E-Mails in der Schweiz besonders zu beachten gilt die Tatsache, dass Mailings – wie die Seite selbst auch – sowohl in deutsch als auch in französisch und italienisch angeboten werden sollte.
Auch bei der Preisgestaltung zeichnen sich neben den unterschiedlichen Währungen Unterschiede ab. Beim Euro ist man es gewohnt Euro und Cent Beträge mit einem Komma zu trennen. In der Schweiz verwendet man zwischen dem Franken und den Rappen (100 Rappen entsprechen einem Franken) einen Punkt. Ebenso steht beim Euro die Währung hinter dem Betrag; beim Franken davor (wie beim amerikanischen Dollar). Ist der Betrag mehr als dreistellig, so verwendet man beim Euro einen Punkt als Tausendertrennzeichen. Da der Punkt beim Franken bereits für das Trennen von Franken und Rappen vergeben ist, wird hier ein Apostroph (Hochkomma, Oberstrich) verwendet. Ein Beispiel:
- 299,99 EUR oder 1.299,99 €
- CHF 1’299.95 oder Fr. 1’299.95
Interessant im Zusammenhang mit der Währung ist außerdem die Tatsache, dass in der Schweizer Währung die kleinste Münzeinheit 5 Rappen sind. Daher sind bei den Schweizer Preisen in der Regel lediglich Nachkommastellen anzufinden, die auf Zehner oder Fünfer gerundet sind.
Unterschiedliche Inhalte aufgrund unterschiedlicher Prioritäten
Um regional passende Inhalte ausspielen zu können, bedarf es zu Beginn einer Analyse der Konkurrenz, der Marktkennzahlen und der Kaufkraft (insgesamt im Land und innerhalb der eigenen Branche), um einen erfolgreichen Rollout überhaupt erst möglich zu machen.
In Deutschland, Österreich und der Schweiz unterscheidet sich das Nutzerverhalten teils deutlich. Dies lässt sich auf die verschiedenen Gewohnheiten innerhalb der unterschiedlichen Kulturen zurückführen. In den beiden Alpenländern Österreich und Schweiz erscheint die absolute Besucherzahl und das Suchvolumen zuerst klein. Dies lässt sich jedoch auf die im Vergleich zu Deutschland geringe Einwohnerzahl zurückführen. Dafür lässt sich in diesen beiden Ländern ein durchschnittlich größerer Warenkorb-Wert und eine höhere CTR beobachten. Dass es sich bei Deutschland, Österreich und der Schweiz um komplett unterschiedliche Kulturen handelt, zeigen auch die teils prägnanten Unterschiede bei den Online-Shoppern in diesen Ländern. Konsumenten in DACH haben unterschiedlich hoch priorisierte Kriterien. Eine Statistik des ECC Köln zeigt die Top 10 der wichtigsten Kriterien für Online-Shopper. Generell lässt sich unter Schweizer Konsumenten über alle Top-10-Kriterien hinweg ein tendenziell geringerer Anspruch an Online-Shops feststellen. Große Unterschiede weisen sich beispielsweise beim Retouren-Service und der Einkaufs-Frequenz auf: Eine unkomplizierte Retourenabwicklung ist für die Schweizer weniger wichtig als den Deutschen und den Österreichern. Hinzu kommt, dass die Schweizer weniger oft im Internet einkaufen als in Deutschland und in Österreich.
In der Schweiz ist zwar sowohl die Smartphonedichte als auch die mobile Nutzung besonders hoch. Eine mobile Seite ist jedoch allein schon wegen dem Ranking quasi Pflicht für jedes Land. Noch viel wichtiger ist die Konzentration auf andere Begebenheiten. Es sollten regional beliebte Marken und Produkte hervorgehoben werden. Es empfiehlt sich außerdem, die Anpassung der Meta-Angaben im HEAD-Bereich um die SERP in den Suchergebnissen besser zu visualisieren. Dies erhöht die Klickrate
Zugegeben, es gibt Firmen, die kommunizieren ihre Herkunft sehr offensiv. Sprich die heimische Kultur wird absichtlich auf diejenigen Länder übertragen in welche die Firma expandiert. Beispiele hierfür sind IKEA (Schwedische Möbel), SWATCH (Uhren mit Schweizer Uhrenwerk), Apple (Designed by Apple in California), Versace (The Italian Fashion Brand), Jever (Friesisches Brauhaus – friesisch herb), Junghans (Die deutsche Uhr), manche Fluggesellschaften und Käsereien. Aber dennoch: Gerade hier gilt ebenfalls die sprachliche Anpassung des vermittelnden Inhalts an die Region, um erfolgreich zu sein. Zusammenfassend lässt sich sagen: Wer aufmerksam die länderspezifischen Bedürfnisse beobachtet und auf seinen Seiten umsetzt, wird langfristig die Herzen der User gewinnen. Alles auf der Website dreht sich um den User und schafft ein Umfeld, welches seinen Bedürfnissen und Gewohnheiten gerecht wird. Denn wer den User schätzt, erhöht das Vertrauen und erzielt somit mehr Traffic und bessere Conversions. Beides hat indirekte Auswirkungen auf das SEO-Ranking.
Unterschiedliche Keywords
Zwar ändert sich der Prozess der Keyword-Recherche an sich nicht, jedoch sollte im internationalen Kontext der Fokus geändert werden. Dei bloße Übersetzung eines rein deutschen Keywords kann ein guter Ausgangspunkt sein. Jedoch sollte vor der Keyword-Analyse das Wort durch einen Mitarbeiter bestätigt werden, der sich mit dem Zielland oder der -region bestens auskennt um vermeintliche Fehler frühzeitig zu vermeiden. Denn jede Sprache, jedes Land und jeder Dialekt bringt seine Besonderheiten mit sich.
So ist es gut möglich, dass ein internationaler Rollout – selbst in gleichsprachigen Ländern – gleichbedeutend ist mit einer neuen Keyword-Liste. Nur so können die richtigen Keywords besetzt werden und auch erfolgreiche länderspezifische Nischen-Keywords belegt werden. Denn nur wer sich in die Lage der Bevölkerung versetzt versteht wonach gesucht wird und kann somit auch erfolgreiches SEO betreiben.
Selbst innerhalb eines Landes können sich schon unterschiedliche Begriffe von Region zu Region unterscheiden. Ein einfaches und greifbares Beispiel für Deutschland ist der Begriff Metzgerei bzw. Fleischerei. Spricht man in den südlichen Bundesländern Deutschlands von einer Metzgerei so ist es in den nördlichen Bundesländern normal, von einer Fleischerei zu reden. Das lässt sich sehr schön in den Google Trends nachverfolgen.

Regionales Interesse des Keywords Brötchen in Deutschland bei Google Trends

Regionales Interesse des Keywords Semmel in Österreich bei Google Trends
Ein Beispiel für einen länderübergreifenden Begriff innerhalb von DACH sind die Wörter Brötchen, Semmel und Weggli.

Regionales Interesse des Keywords Brötchen in Deutschland bei Google Trends
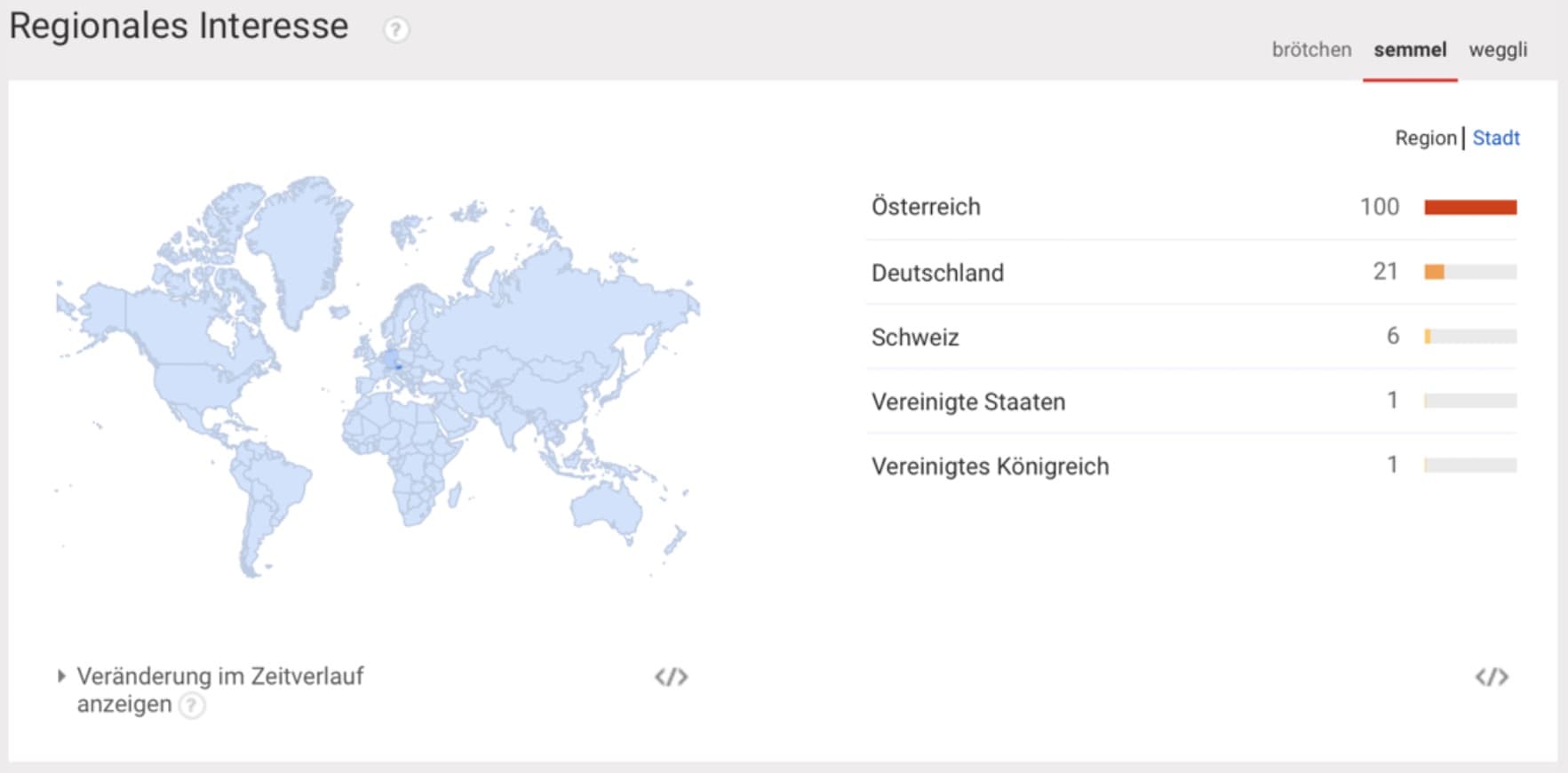
Regionales Interesse des Keywords Semmel in Österreich bei Google Trends

Regionales Interesse des Keywords Weggli in der Schweiz bei Google Trends
Der Begriff Brötchen wird meistens in Deutschland verwendet, das Wort Semmel in Österreich und Bayern (Deutschland) und das Keyword Weggliausschließlich in der Schweiz. Diese beiden Beispiele lassen sich auf viele Dinge im Alltag übertragen. Auch in der Elektronik und sonstigen in Online-Shops erhältlichen Waren entstehen immer wieder unterschiedliche Begrifflichkeiten – nicht nur im Vergleich zu anderen Sprachen, sondern auch im Vergleich zu Dialekten. Spricht man in Deutschland und den meisten Teilen Österreichs von einem Handy, ist in der Schweiz viel mehr der Begriff Natel gängig. Aber auch in anderen Branchen machen sich Unterschiede in der Sprache bemerkbar: Betreibt man beispielsweise einen Online-Shop für Motorräder in Deutschland, so sollte stets bedacht werden, dass der gleichbedeutende Begriff in der Schweiz Töff ist. Um nicht in eine sprachliche Falle zu tappen, sollte aus diesem Grund jeder Website-Betreiber bei einem Rollout einer Webpräsenz in andere Länder in jedem Fall den Inhalt und vor allen Dingen die Keywords an die regionalen Gegebenheiten adaptieren. So wird man nicht nur dem Nutzer gerecht, sondern erzielt auch mit SEO ein besseres Ranking. Viele Begriffe lassen sich nicht eins zu eins in eine andere Sprachregion oder gar Sprache übertragen. Hilfreich sind in jedem Fall Muttersprachler, welche die Sprache gut beherrschen und sich in der Sprachregion bestens auskennen.
Fazit zum internationalen Onpage-SEO
Umso größer der Online-Shop, desto eher sind alle oben genannten Kriterien und Punkte für internationales Onpage-SEO erfüllt. Bei vielen Online-Shops kann der regionale Content sicherlich noch weiter ausgebaut werden. Das gilt gerade für Seiten, die von Deutschland z.B. in die Schweiz und nach Österreich expandieren. Zalando beispielsweise wurde 2008 in Deutschland gegründet und ist 2011 in die Schweiz expandiert. Die Startseiten von zalando.de und zalando.ch zeigen in Deutschland und der Schweiz neben einer anderen Währung sowohl andere Inhalte als auch bei gleichen Inhalten unterschiedliche Texte und Beschriftungen.
Interessante Ergebnisse lassen sich auch in Bezug auf die Keyword-Kannibalisierung beobachten. Bei großen Online-Shops kommt es schnell vor, dass sich die eigenen Produkte untereinander sowohl in der eigenen Suche im Shop als auch in den Suchmaschinen konkurrieren. Um der unübersichtlichen Vielfältigkeit an Produktausführungen Herr zu werden nutzen die Shop-Betreiber unterschiedliche Lösungen. Mit gutem Beispiel geht hier Amazon voran. Produkte, die in verschiedenen Ausführungen in diesem Shop erhältlich sind, werden hier sinnvoll optimiert. Als Beispiel dient der Schuh Converse Unisex-Erwachsene Chuck Taylor All Star-Ox Sneaker. Dieser Schuh ist in allen Schuhgrößen zwischen 36 und 46 und in mehreren verschiedenen Farben erhältlich. Insgesamt ergeben sich somit schnell über 100 bestellbare Produktausführungen. Über die Select-Box neben dem Produktbild sind die Schuhgrößen anwählbar. Über die farbigen Produktbilder unter jener Select-Box sind die Farbvarianten wählbar. Die erste Variante ist hierbei vorausgewählt und stellt somit den Hauptartikel dar. Aufrufbar ist dieser unter der URL https://www.amazon.de/CONVERSE-Seasonal-Unisex-Erwachsene-Sneakers-Schwarz/dp/B000OLTRYU/. Aus diesem Haupt-Produkt heraus lassen sich alle möglichen Versionen des Artikels ableiten. Die URL-Struktur darf man hingehend soweit verstehen, dass das Element /dp und das nachfolgende URL-Element /B000OLTRYU vergleichbar mit GET-Parametern sind. Letzteres ist die eindeutige Identifikation zu einer bestimmten Produktausführung und somit vergleichbar mit einer Artikelnummer. Der Parameter /B01DWURDEK beispielsweise ist die eindeutige Bezeichnung für den Schuh in der Größe 43 in der Farbe weiß. Ausnahmslos alle Varianten dieses Produkts weisen mit einem Canonical-Tag auf den Haupt-Artikel. Somit wird bestmögliche Suchmaschinen-Optimierung betrieben, da gewährleistet ist, dass die Produkte sich in Google nicht untereinander konkurrieren. In der eigenen Shop-Suche von Amazon sind die einzelnen Produkt-Varianten bei gezielten Suchanfragen dennoch auffindbar.



Nimm an der Diskussion teil Ein Kommentar